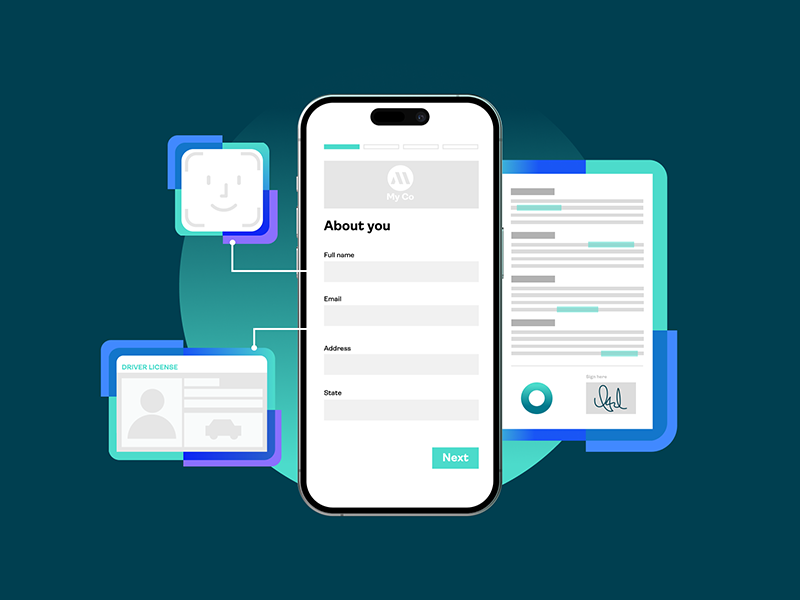
Every digital customer interaction provides an organization with the opportunity to deliver an impactful experience and build trust. Yet the digital experience customers have online often doesn&rsquo…
Now that digitalization has become ubiquitous and remote work is here to stay, organizations worldwide are grappling with the challenges a dispersed workforce can bring. Chief among these concerns is…
In part one of this blog series, we provided an overview of the NIS2 Directive. Here in part two, we cover a specific aspect of NIS2: Requirements and timelines for compliance as it relates to strong…